[llama.cpp]를 WSL에서 빌드 및 실행하기

[llama.cpp]를 WSL에서 빌드 및 실행하기
llama.cpp를 알게된 경위와 설치방법에 대해 정리해둔다.
llama.cpp를 어떻게 알게 되었나?
Ollama를 통해서 로컬 LLM을 사용하고 있었는데, 현재 시스템에 알맞는 모델이 뭐가 있을까 찾아보던 중 reddit에서 댓글을 하나 보았다.
“모델도 모델인데 Ollama 대신 llama.cpp를 쓰는걸 강력 추천한다.”
이렇게 추천하는건 필시 이유가 있을 것이기에 알아보게되었다.
llama.cpp가 뭔가?
llama.cpp는 한 줄로 요약하면 “대규모 언어 모델을 GPU 없이도 빠르고 가볍게 실행할 수 있게 만든 오픈소스 LLM 추론 엔진”이다.
장점
- 압도적인 속도: C++ 기반이라 추론 속도가 매우 빠르다. 실제 벤치마크 테스트에서 Ollama 대비 13%~80% 빠른 성능을 보인다.
- 세밀한 제어: 모델 파라미터, 메모리 사용량, GPU 활용 방식 등을 개발자가 직접 설정할 수 있다.
- 다양한 하드웨어 지원: CPU, NVIDIA GPU, Apple Silicon, 심지어 라즈베리파이 같은 저사양 기기에서도 작동한다.
Ollama와의 관계
Ollma는 내부적으로 llama.cpp를 활용하는 대표적인 프로젝트 중 하나다.
즉:
- llama.cpp -> 엔진
- Ollama -> 사용하기 쉽게 감싼 플랫폼
이라고 이해하면 쉽다.
Ollama는 모델 다운로드,실행,API 제공을 자동화해 초보자도 쉽게 로컬 LLM을 사용할 수 있게 만든다.
설치 방법
기본 빌드 도구 및 라이브러리 설치
1
2
sudo apt update
sudo apt install -y build-essential git cmake libcurl4-openssl-dev libssl-dev pkg-config
NVIDIA CUDA Toolkit 설치
1
2
3
4
5
6
7
8
9
10
11
12
# CUDA 리포지토리 PIN 파일 다운로드 및 이동
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
# CUDA 리포지토리 GPG 키 다운로드 및 추가
wget https://developer.download.nvidia.com/compute/cuda/12.5.1/local_installers/cuda-repo-wsl-ubuntu-12-5-local_12.5.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-5-local_12.5.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-5-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
# CUDA Toolkit 설치
sudo apt-get -y install cuda-toolkit-12-5
CUDA 환경 변수 설정
1
2
3
4
5
6
# .bashrc 파일에 환경 변수 추가
echo 'export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc
# 변경된 설정 즉시 적용
source ~/.bashrc
llama.cpp 소스코드 다운로드 및 컴파일
CMAKE_CUDA_ARCHITECTURES는 RTX 30xx이면 86, RTX 40xx이면 89
1
2
3
4
5
6
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
mkdir build
cd build
cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 -DLLAMA_OPENSSL=ON
cmake --build . --config Release
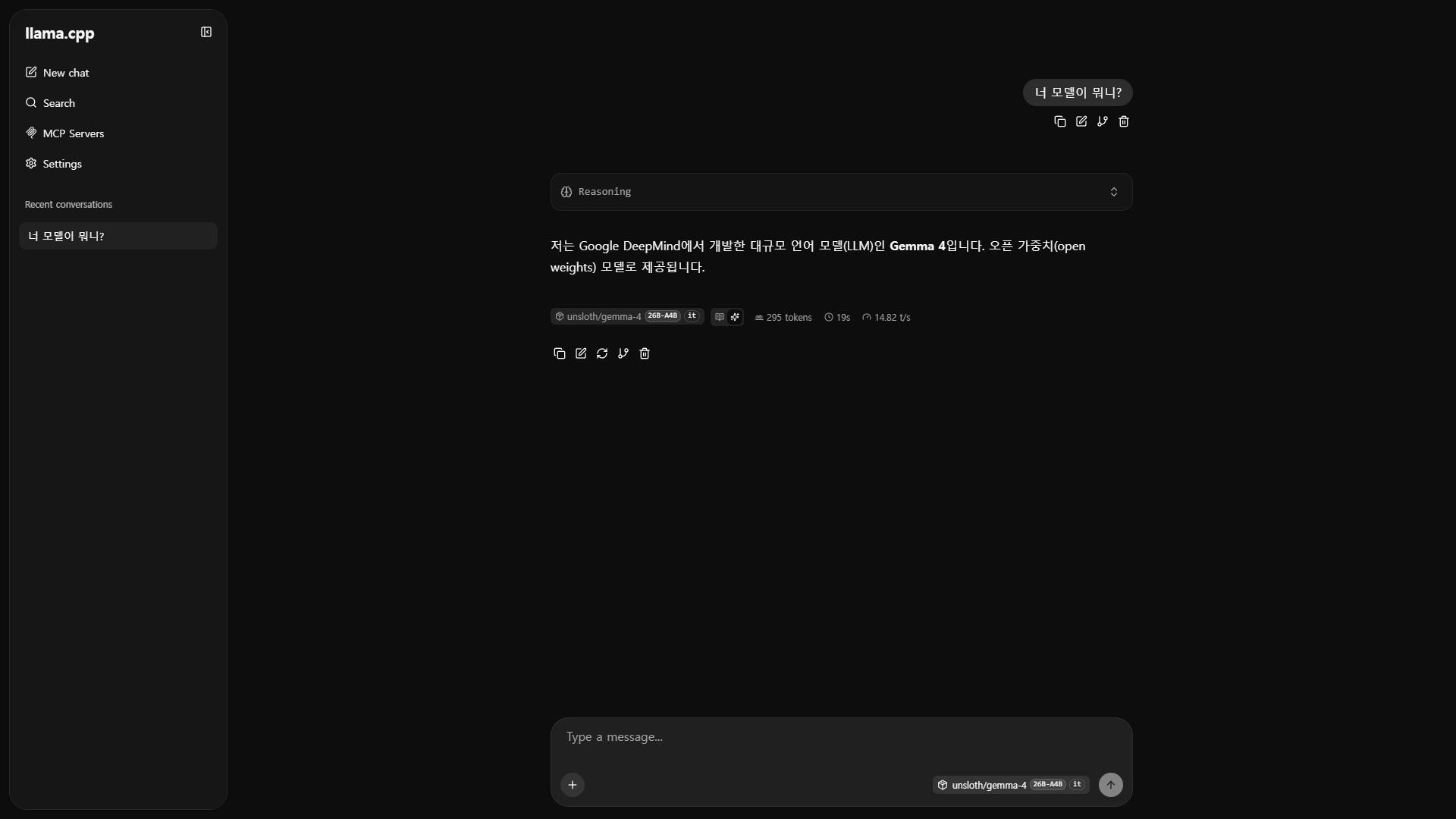
API 서버 실행 및 확인
c 4096
: 컨텍스트 크기. 모델이 한 번에 기억하고 처리할 수 잇는 대화의 양이다.ngl 999
: GPU에 올릴 레이어 수. 여기에 아주 큰 숫자를 넣으면 llama.cpp가 “가능한 모든 레이어를 GPU에 올려라”라고 알아서 해석한다.
1
./bin/llama-server -hf unsloth/gemma-4-26B-A4B-it-GGUF -c 4096 -ngl 999 --host 0.0.0.0 --port 8000
http://localhost:8000 으로 접속하면 llama.cpp가 표시된다.
출처
This post is licensed under CC BY 4.0 by the author.